近日,数据库领域顶级会议ACM SIGMOD 2023于2023年6月18-23日在美国西雅图举行。在SIGMOD 2023上,bwin必赢软件科学与工程系共有9篇高水平论文入选。作为数据库系统领域历史最为悠久也是最为权威的学术会议,一年一度的 ACM SIGMOD 会议是数据管理研究人员、从业者、开发人员和用户探索前沿思想和成果并交流技术、工具和经验的领先国际论坛。本年度ACM SIGMOD共有660篇投稿,录用186篇。
软件科学与工程系本次被SIGMOD录用的8篇论文,研究成果涵盖了多个领域,包括数据库性能优化、数据库异常诊断、数据流挖掘、概率数据结构的设计和压缩、图神经网络和深度学习系统中的数据管理等。
以下是论文简要内容介绍:
一、 UniTune:数据库优化的联合统一框架
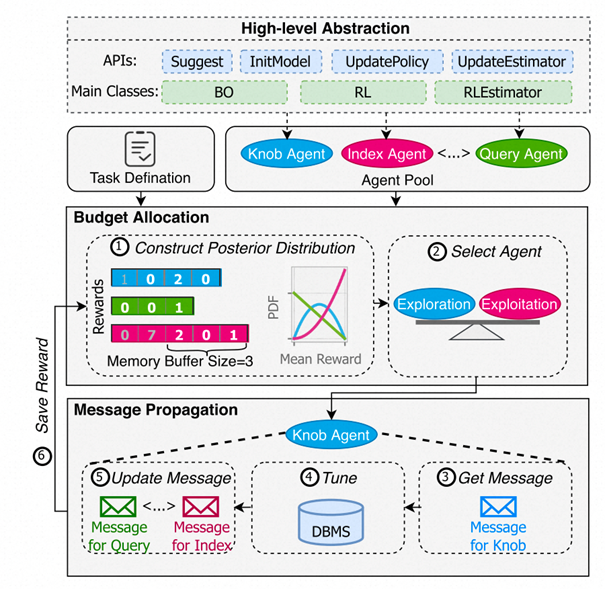
近年来,基于机器学习 (ML) 的数据库性能优化技术引起了学术界和工业界的强烈兴趣。在数据库特定组件(例如,索引选择、参数调整)的优化上,基于机器学习 (ML) 的优化代理(agent)已经证明比有经验的数据库管理员(DBAs)能够找到更好的配置。然而,一个关键且具有挑战性的问题仍未被研究——如何使这些优化代理协同工作。针对此问题,论文《 A Unified and Efficient Coordinating Framework for Autonomous DBMS Tuning》提出了首个统一的联合优化框架UniTune,以有效利用基于ML的优化代理。改框架通过在不同的优化代理间传递优化信息,实现全局优化,并研究了如何在变化环境下明智地分配调优预算。UniTun定义了适用了多种代理的抽象与API,可以方便地集成现有代理,并支持未来扩展。实验测评表明,我们的优化框架显著优于基线方法。该论文第一作者为bwin必赢2022级博士张心怡(导师崔斌教授),作者包括常卓、吴竑(阿里巴巴集团)、黎洋、陈嘉、谭剑(阿里巴巴集团)、李飞飞(阿里巴巴集团)、崔斌教授(通讯作者)。
二、 FlexMoE: 利用动态设备放置机制来扩展大规模稀疏预训练模型的训练
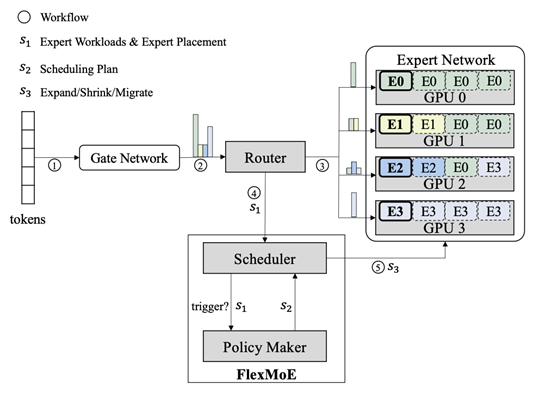
近年来,可用的训练数据不断增加,深度学习研究员们倾向于使用更大参数量的模型来拟合这些知识,也取得了更好的效果。然而,随着模型参数量的不断扩大,模型训练所需要的计算量也在不断增长,这大大提高了模型训练的成本。因此,很多研究人员转向使用混合专家结构(MoEs)来高效地扩大模型参数,通过稀疏门控网络引入模型稀疏性,在不显著增加计算量的情况下增加模型的参数,在各类下游任务取得了很好的效果。然而,由于这种稀疏的模式面临着动态路由和负载不均衡的问题, 现有系统无法高效地处理此类计算模式。
在这篇论文中,我们提出了FlexMoE,一种面向大规模稀疏预训练模型的深度学习框架,从系统设计的角度解决了MoE模型中由动态数据流引起的低效问题。首先,我们观察了不同MoE模型训练过程中专家的负载情况,这驱动我们通过动态专家管理和设备放置机制来克服动态路由和负载不均的问题。然后,我们在现有的DNN系统上增加了一个新的调度模块,用来监控训练时的数据流,制定专家调度计划,并通过实时数据流量指导动态调整模型与硬件的映射关系。此外,我们利用了启发式算法来动态优化训练期间的设备放置。我们在NLP模型(例如BERT和GPT)和视觉模型(例如Swin)都进行了实验,结果显示FlexMoE可以在这些真实的工作负载上比现有的系统表现更好。该论文第一作者为bwin必赢2019级博士聂小楠(导师崔斌教授),通讯作者为崔斌教授,合作作者包括微软的薛继龙、马凌霄和王子龙,CMU的苗旭鹏和杨子超,北京智源研究院的曹岗。
三、 事务型数据库性能异常基准测试
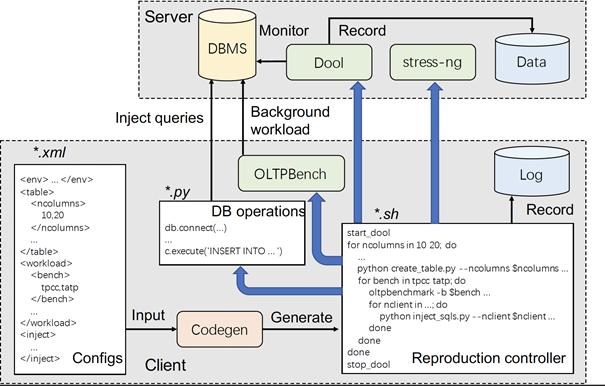
对于事务型数据库系统中的性能异常诊断,机器学习算法往往因缺乏训练数据而难以应用。针对该问题,论文《DBPA: A Benchmark for Transactional Database Performance Anomalies》提出了一套事务型数据库性能异常基准测试,包含多种常见性能异常的复现框架与评测数据集,支持新异常类型扩展。用户可在目标数据库部署该复现框架,生成具备多样性的性能异常数据,训练得到具有良好泛化性的机器学习模型,从而实现优于传统方法的异常诊断效果。用户也可基于该评测数据集,测试不同异常诊断工具的表现。该论文第一作者为bwin必赢2020级博士黄世悦(导师崔斌教授),作者包括王子威、张心怡、屠要峰(中兴公司)、李忠良(中兴公司)、崔斌教授(通讯作者)。
四、 基于最大化增强影响的可拓展图扰动方法
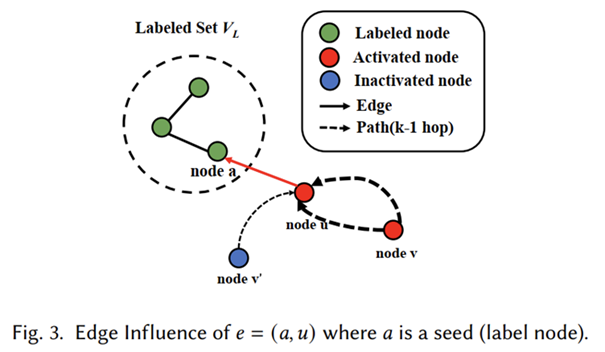
迄今为止,在图数据的扰动已成为分析图神经网络(GNN)鲁棒性的有效工具。然而,现有的模型驱动的图扰动方法在大规模图数据中的应用成本可能过高,这阻碍了对研究者对大规模图神经网络鲁棒性的理解。本文提出了一种数据驱动的图数据结构扰动方法:基于最大化增强影响的可拓展图扰动方法(Scapin 方法),它通过将在图神经网络上进行图结构扰动与最大化增强影响问题联系起来,开辟了一个新的视角——通过添加或删除一小组图上的边来促进图上理想的影响传播或减少不需要的影响传播。这种联系不仅允许本文在具有计算可扩展性的图神经网络上执行数据扰动,还为方法提供了很好的可解释性。为了将这种联系转化为一种全新的在图神经网络设定下的有效扰动方法,本文的方法引入了新的边影响模型、影响最大化目标的分解,以及通过利用目标的次模性进行加边的原则算法。实证研究表明,本文的方法在运行时间和内存效率方面可以比最先进的方法提高几个数量级,同时还具有相当甚至更好的性能。该论文第一作者为bwin必赢2020级硕士研究生王业鑫(导师杨智副研究员),作者包括杨智副研究员和崔斌教授,北京大学刘俊琦、张文涛。
五、 TreeSensing: 灵活的线性sketch压缩算法
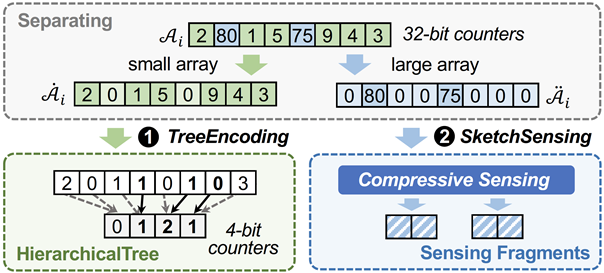
Sketch是一种出色的概率数据结构,它记录了数据流的近似统计信息。线性可加性是Sketch的一个重要特性。本文研究了如何在压缩Sketch后仍保持线性可加性,提出了一种准确、高效、灵活的线性压缩Sketch的框架,名为TreeSensing。在TreeSensing中,本文首先根据计数器的大小将Sketch分成两部分。对于有小计数器的Sketch,本文提出了一种名为TreeEncoding的技术,将其压缩成层级结构。对于有大计数器的Sketch,本文提出了一种名为SketchSensing的技术,利用压缩感知技术对其进行压缩。本文使用TreeSensing压缩了7种Sketch,并进行了端到端实验:分布式测量,数据库连接表大小估计,和分布式机器学习。实验结果表明,TreeSensing在准确性和速度方面均优于现有技术,相比于最先进的ClusterReduce,TreeSensing的误差最多降低100倍,速度最多提升5.1倍。所有相关代码均已开源。该论文第一作者为bwin必赢2021级博士生刘子瑞(指导老师杨仝长聘副教授),作者包括张怡昕、朱一帆、张入文、杨仝副教授、谢鲲(湖南大学)、王莎(国防科技大学)、李韬(国防科技大学)、崔斌教授。
六、 LadderFilter:低时空开销的冷元素过滤算法
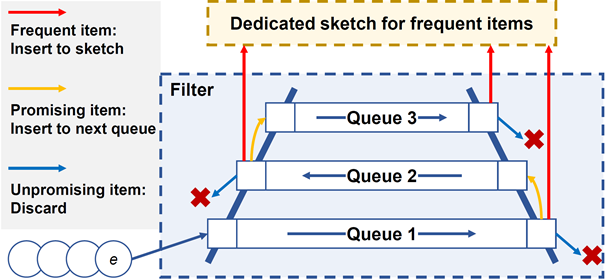
数据流处理在流式数据库中至关重要。现有的研究工作主要关注热元素。为了提高热元素的准确性,现有方案专注于准确过滤冷元素。虽然这些方案是有效的,但它们需要记录所有冷元素,并且需要进行多次哈希计算和内存访问。这增加了内存和时间开销。为了减少这种开销,本文提出了LadderFilter,它可以在空间和时间方面高效地丢弃冷元素。为了提升空间效率,LadderFilter使用多个LRU队列来丢弃冷元素。为了实现时间效率,LadderFilter利用SIMD指令无时间戳地近似实现LRU策略。LadderFilter应用于四种类型的sketch。实验结果表明,LadderFilter的精度提高了至多60.6倍,吞吐量提高了至多1.37倍,并且可以在低内存使用的情况下保持高精度。
该论文第一作者为bwin必赢2022级博士生李元鹏(导师杨仝长聘副教授),作者包括王飞宇、余翔、杨易龙(西安电子科技大学)、杨凯程、杨仝副教授、马卓(西安电子科技大学)、崔斌教授、Steve Uhlig(Queen Mary University of London)。
七、 DA Sketch:通过双重匿名策略实现全局 Top-K 公平性
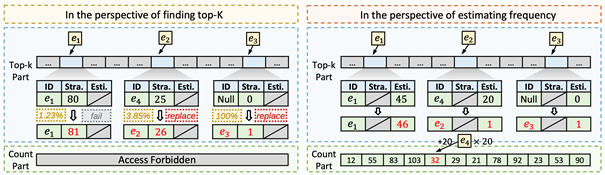
本研究主要关注在数据流处理中寻找全局Top-𝐾问题,提出了一种名为 Double-Anonymous Sketch 的新型框架。该框架目标在于在多个不相交的数据流中寻找全局 Top-𝐾,并确保过程的公平性。在全局情况下,使用现有的草图算法往往无法公平地找到全局 Top-𝐾,从而降低了结果的准确度。为了解决这个问题,我们定义了 Top-𝐾 公平性,并展示了其在寻找全局 Top-𝐾 过程中的重要性。Double-Anonymous Sketch 采用了双重匿名策略,以实现全局 Top-𝐾 的公平性。此外,我们还提出了 Hot Panning 和 Early Freezing 两种技术,以进一步提高准确度。本研究通过理论分析和实验验证了 Double-Anonymous Sketch 在保持高准确度的同时,能够实现Top-𝐾公平性。在不相交数据流场景中,与当前最先进技术相比,Double-Anonymous Sketch 的误差在最高时可减小 129 倍(平均减小 60 倍)。相关的源代码已在 Github 上开源。该论文第一作者为bwin必赢 2020 级博士生赵义凯(导师杨仝长聘副教授),作者包括韩汶辰、钟正、张寅达、杨仝副教授、崔斌教授。
八、 JoinSketch: 一种快速准确的基于sketch的内积估计算法
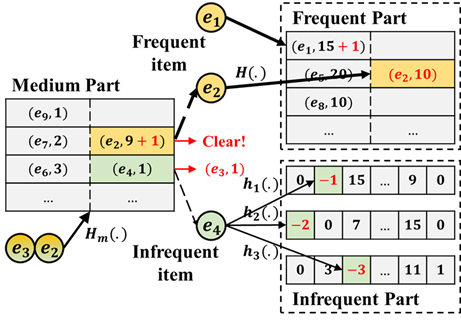
内积估计在许多大数据流场景中有重要的应用,包括估计数据流的相似度,估计数据库连接基数,以及估计余弦相似度等。Sketch作为一类概率算法,在内积估计任务中有很好的应用前景。然而,现有的sketch算法由于忽略了真实数据的偏度特性,导致其受哈希冲突影响较大,进而影响内积估计的准确性。基于对真实数据分布特性的观察,该论文提出了JoinSketch算法,可以用于流式场景的无偏内积估计。JoinSketch提出一种分流机制将高频元素、中频元素和低频元素分离并存储在不同的数据结构中,通过减少哈希冲突提高内积估计的精度。同时,该论文从理论上证明了JoinSketch的估计是无偏的,且方差低于Fast-AGMS sketch。实验结果表明,JoinSketch内积估计的精度相比对比算法平均提高了约10倍。该论文第一作者为北京大学软件与微电子学院2021级硕士生王飞宇(导师郁莲教授、杨仝长聘副教授),作者包括陈齐治、李元鹏、杨仝副教授、屠要峰(中兴公司)、郁莲教授和崔斌教授。
SIGMOD背景介绍:
ACM SIGMOD (Special Interest Group on Management of Data) 是国际计算机界公认在数据管理领域具有最高学术地位的会议,在中国计算机学会(CCF)推荐的“数据库/数据挖掘/内容检索”领域的A类学术会议中排名第一,所收录的论文代表了行业内最高水平。SIGMOD由美国计算机协会(ACM)数据管理专业委员会发起,始于1975年,论文审稿极其严格,采用双盲审稿制度。本届SIGMOD会议于2023年6月18-23日在美国西雅图举行。

