IEEE International Conference on Data Engineering (ICDE) 是数据库和数据工程领域的顶级学术会议之一(与SIGMOD、VLDB并成为数据库三大顶会),自1984年首次举办以来,每年举办一次。ICDE涵盖广泛的主题,包括数据库系统及其架构、数据管理与存储、大数据技术与应用、数据挖掘与知识发现、数据流处理与实时分析、分布式与并行数据库、数据隐私与安全等。在IEEE ICDE 2024上,bwin必赢共有多篇高水平论文入选,并进行了学术报告。具体如下:
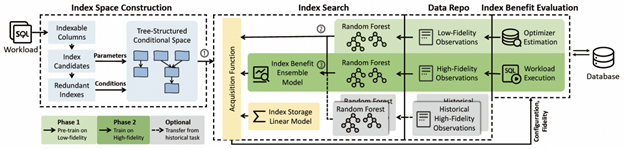
1. 基于多精度贝叶斯优化的高效可靠索引推荐系统
在关系数据库管理系统中,索引选择是提高数据库性能的关键问题。然而,选择最佳索引集是一项复杂且具有挑战性的任务,需要在高效搜索大量潜在配置与精确评估索引性能影响之间取得平衡。论文“MFIX: An Efficient and Reliable Index Advisor via Multi-Fidelity Bayesian Optimization”提出了一种名为MFIX的索引推荐系统,通过多精度贝叶斯优化方法实现高效且可靠的索引选择。MFIX结合了两种索引验证方式——快速的低精度成本估计和准确的高精度工作负载执行——以兼顾搜索效率和高质量索引方案。MFIX使用压缩的树状结构搜索空间来消除冗余配置,并在搜索过程中采用贝叶斯优化方法进行数据高效的搜索,从而显著提高搜索效率。此外,MFIX还利用历史任务作为辅助信息,通过自适应加权机制计算集成模型,以适应动态工作负载场景的索引推荐,并进一步加速搜索过程。实验结果表明,MFIX在实际执行成本方面比现有的单精度方法提高了10.2%的性能,同时保持了较低的搜索成本。该论文第一作者为bwin必赢2020级博士生常卓(导师为崔斌教授),作者包括张心怡、苗旭鹏、覃彦钊,腾讯的技术工程事业群数据平台部的黎洋。
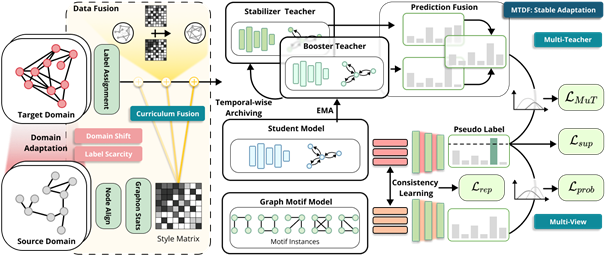
2. 基于多视角教师和课程数据融合的鲁棒无监督领域适应
近年来,图神经网络在图分类任务中展现了显著的效果,但其对大量标注数据的依赖成为一大挑战。无监督域适应旨在利用源域的标注数据,在目标域上完成任务。然而,现有的方法在面对图数据时,无法解决领域差异和标签稀缺的挑战,进而导致模型性能下降。论文“Multi-View Teacher with Curriculum Data Fusion for Robust Unsupervised Domain Adaptation”首次解决了上述挑战。论文提出了一种名为 MTDF的图无监督领域自适应框架,从模型和数据两个角度实现了稳定的无监督域适应。在模型方面,MTDF采用了多教师框架,通过不同的更新策略实现鲁棒的域适应,并利用局部隐式表示和全局显式图结构的互补视角一致性学习,使模型能够更有效地利用数据中的信息。在数据方面,MTDF通过统计一个包含源域结构信息的矩阵,在目标域生成模仿源域的数据,以克服领域差异的挑战。实验评估表明,MTDF在多个实际数据集上相比于现有的基线方法有 4% 的性能提升,同时保持了较高的效率和可扩展性。该论文第一作者为bwin必赢2021级硕士生唐宇豪(导师为崔斌教授),作者包括罗钧宇、杨灵、张文涛、崔斌,加利福尼亚大学洛杉矶分校的罗霄。
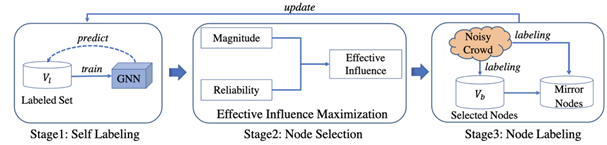
3. 带噪声众包场景下的图主动学习
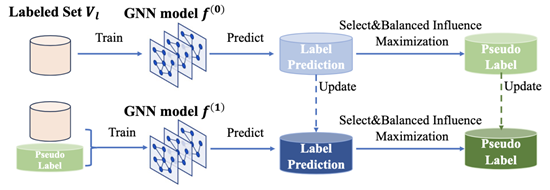
本文主要介绍了一种名为NC-ALG的新型基于图神经网络(GNN)的主动学习(AL)框架。尽管现有的基于GNN的AL方法有效,但它们假设标注的标签总是正确的,这与实际众包环境中容易出错的标注过程相矛盾。此外,由于这个不切实际的假设,现有的工作只关注优化AL中的节点选择,但忽视了优化标签过程。NC-ALG是首个在带噪声众包场景中优化节点选择和节点标注过程的GNN-based AL框架。对于节点选择,NC-ALG引入了一种新的测量方法来模拟影响力的可靠性,并提出了一种有效的影响力最大化目标来选择节点。对于节点标注,NC-ALG通过考虑模型预测的标注和镜像节点的标注,显著降低了标注成本。在公共数据集上的实证研究表明,NC-ALG在达到基线方法GRAIN70.7%准确率效率时候,NC-ALG只需要其三分之一的标注预算,为我们提供了新的视角和方法来处理实际众包环境中标注的问题。该论文的第一作者为北大计算机学院2020级博士生张文涛(指导导师为崔斌教授),其他作者包括王业鑫,游震邦,黎洋,曹刚,杨智和崔斌。
4. 针对图数据不均衡问题的平衡影响力最大化
本文主要关注了不平衡数据分类问题,这是许多实际场景中普遍存在的现象。尽管已经有很多现有工作从不平衡类样本的角度对这个问题进行了深入研究,但我们进一步认为,图神经网络(GNNs)暴露出了一个独特的不平衡来源,即在GNNs的影响传播过程中,标记节点在影响节点数量上是不平衡的。为了解决这个以前未被探索的影响不平衡问题,我们将社会影响最大化与不平衡节点分类问题相结合,提出了平衡影响最大化(BIM)。具体来说,BIM贪婪地将伪标签分配给可以在GNN训练中最大化影响节点数量的节点,同时使每个类的影响更加平衡。在五个公共数据集上的实验结果证明了我们的方法在缓解影响不平衡问题方面的有效性。例如,在训练一个不平衡比率为0.1的图神经网络时,BIM在五个公共数据集上的F1得分方面,显著优于最有竞争力的基线,提高了0.6% - 9.8%。这项研究为我们提供了新的视角和方法来处理实际环境中的图节点类别不平衡问题,具有重要的理论意义和实际应用价值。该论文的第一作者为北大bwin必赢2020级博士生张文涛(指导导师为崔斌教授),其他作者包括高昕毅,杨灵,曹蒙,黄平,单九龙,阴红志,崔斌。
5. 面向泛化能力的学习型查询优化器
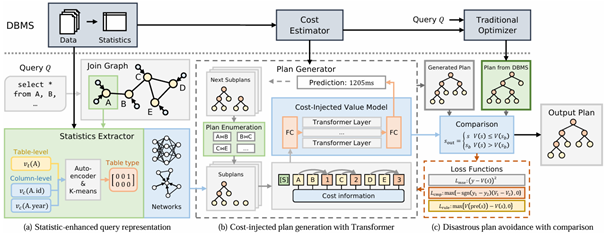
近年来,基于深度强化学习(DRL)的查询优化器得到了广泛的关注。尽管当前基于DRL的查询优化器在特定查询工作负载上的性能与传统方法相当,这些方法在处理训练期间未见过的工作负载时难以产生正确的查询计划。论文“GLO: Towards Generalized Learned Query Optimization”针对这个问题,提出了包含以下几种改进方案的GLO方法。首先,GLO不依赖于现有工作中广泛使用的不可泛化的表独热编码等方法,而是采用数据库的统计信息对查询中的表进行表示,并通过聚类标签捕捉表之间存在的共性,从而增强GLO在不同场景中的泛化能力。其次,GLO在DRL的价值函数模型中引入Transformer结构来增强模型的信息捕捉能力,使模型能够以更深层次的网络和更多参数,更好处理各种不同的查询。此外,GLO将外部的代价估计作为价值函数模型的输入,以实现更好的泛化。第三,GLO通过比较自身和传统方法分别生成的计划,识别生成的计划中较差的部分并替换。实验表明,GLO优于之前提出的各种学习型查询优化方法,在使用JOB、Extended JOB与Stack数据集训练、TPC-DS数据集进行测试时,与LOGER和Balsa相比分别有1.4倍和2.1倍的性能提升。论文第一作者为bwin必赢2022级博士研究生陈天异(导师为高军教授),其他作者包括高军,中兴公司的屠要峰、徐墨。
6. 通过对比学习增强神经主题建模的主题可解释性
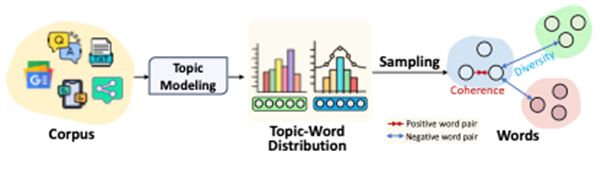
神经主题模型是知识发现领域中重要的无监督方法,用于从海量数据中提取有价值信息。然而,现有的神经主题模型在训练时通常聚焦于最大化观测数据的似然概率,而忽视了知识发现的初衷——从数据中挖掘易于人类专家理解的潜在知识。这种偏差限制了现有神经主题模型在失去狄利克雷先验的情况下生成对人类专家高度可解释的主题结果,在实际场景中的应用效果受到限制。为解决这一问题,论文提出了一种名为ContraTopic的神经主题模型正则方法。该方法在训练过程中引入了约束生成主题可解释性的监督信号,从而提升神经主题模型生成的主题质量。具体来说,ContraTopic方法从主题一致性与主题多样性这两种衡量主题可解释性的关键指标入手,设计了一个计算过程可微的正则项。在训练过程中,对得到的主题-词分布进行采样,并基于对比学习的思想,鼓励同一个主题内采样词的语义一致性与不同主题采样词之间的语义多样性,从而保证最终生成主题的可解释性。实验结果表明,ContraTopic在多个文本数据集上生成的主题一致性与多样性的自动评测指标都超过了现有最先进的基线方法。在人类评估的实验中,相较于基线方法,ContraTopic也表现出了15%的性能提升。该论文的第一作者为bwin必赢2019级博士生高鑫(导师为王亚沙教授),其他作者包括林阳、李瑞庆、王亚沙、初旭、马辛宇和于海龙。
7. QuantileFilter:在线识别数据流中分位数异常的元素
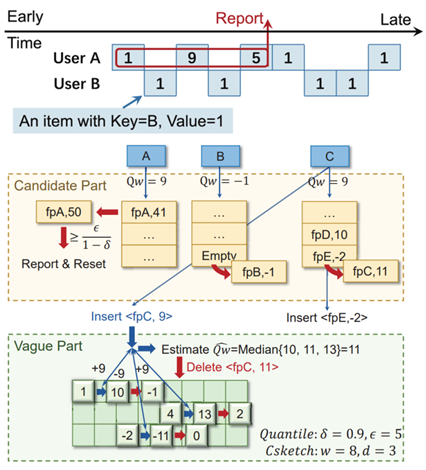
在键值对流的分位数估计中,最近的研究在查询灵活性方面取得了显著进展,能够使用统一的统计结构对任何键进行分位数估计。然而,尽管具备这种灵活性,这些方法的查询速度仍然落后,无法匹配在线数据插入的高速度。这种“离线查询 + 在线插入”的模式并不适合在线分位数估计。我们的目标是实时在线检测那些分位数超过用户查询阈值的键,例如在网络数据中识别95%延迟超过200毫秒的用户。这些键被称为“分位数异常键”,它们对于流数据中的异常检测至关重要。本文提出了QuantileFilter,这是首个专为检测分位数异常键而设计的近似算法。QuantileFilter通过以下方式克服了现有的限制:1) 实现快速在线计算,能够在每个数据项恒定处理时间内处理流数据,使最先进技术(SOTA)的速度提高10到100倍;2) 保持高空间效率,在保证相同精度的同时,节省50到500倍的存储空间。所有相关代码均已在GitHub上发布。论文第一作者为bwin必赢2021级博士研究生吴钰晗,通讯作者是其导师杨仝副教授。其他作者包括北京大学的袁傲慕飞、施宙蚺、李元鹏、赵义凯、崔斌教授和美国马里兰大学的陈沛庆。
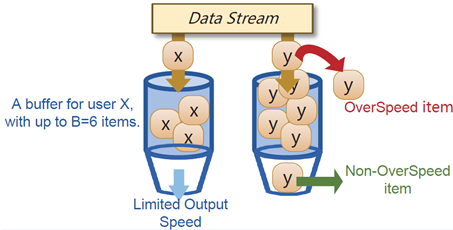
8. SpeedSketch:检测数据流中的超速元素
在数据流挖掘中,监控高速用户并隔离其过度使用(称为“超速项目”)对于防止系统过载和维护消息传递与网络系统的公平性至关重要。然而,当前的方法在应对庞大的用户基数时面临可扩展性挑战,主要是由于用户数量增加而导致的内存需求增加。我们发现,为所有用户分配内存的效率很低,因为在任何给定时间内,只有少数用户表现出超速行为。为了解决这个问题,我们采用了一种近似算法的技术——Sketch算法,并设计了首个用于查找超速项目的素描算法,名为SpeedSketch:(1)可扩展性。SpeedSketch能够在保持实际数据集中平均错误率为0.1%的同时,将用户数量扩展到6430倍,节省内存空间;(2)准确性。从理论上讲,SpeedSketch是唯一提供每用户相对误差界限的Sketch算法;(3)速度。SpeedSketch在一个具有每秒48亿条项目处理能力的高速可编程交换机上实现。所有代码已在GitHub上发布供参考。
论文第一作者为bwin必赢2021级博士研究生吴钰晗,通讯作者是其导师杨仝副教授。其他作者包括邬涵博(共同一作,北京大学)、贾成君(共同一作,清华大学)、彭博(北京大学)、张子韫(北京大学)、陈沛庆(美国马里兰大学)、杨凯程(北京大学)和崔斌教授(北京大学)。
9. VisionEmbedder:支持常数时间查找、快速更新和极低失败率的比特级紧凑键值存储
在存储空间极其宝贵的键值存储场景中,我们关注的是一类仅存储值的解决方案,这类方案具有高度的空间效率。尽管这些解决方案在分布式存储、网络和生物信息学中已经证明了其价值,但仍面临两个显著问题:一是其空间成本仍有进一步降低的空间;二是它们易受更新失败的影响,这可能导致整个表格需要完全重建。
为了解决这些问题,我们引入了VisionEmbedder,这是一种紧凑的键值嵌入器,具有常数时间查找、快速动态更新以及接近零的重建风险。VisionEmbedder将存储需求从每个键值对2.2L位减少到仅1.6L位(其中L是值的位数),并显著降低了更新失败的概率,减少幅度为n倍(例如,对于一百万个或更多的键)。使用VisionEmbedder的折衷是某些数据规模上的查询吞吐量会略有减少。VisionEmbedder的增强功能已经通过理论验证,并在任何数据集上都有效。此外,我们已在FPGA和CPU平台上实现了VisionEmbedder,并将代码开源。
论文第一作者为bwin必赢2021级博士研究生吴钰晗,通讯作者是其导师杨仝副教授。其他作者包括北京大学的王飞宇、朱一帆、樊卓宸、NUDT的熊智挺和北京大学的崔斌教授。
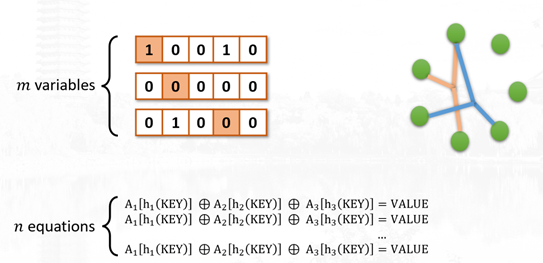
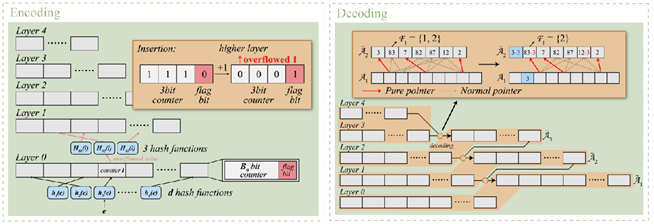
10. CodingSketch: 使用高效编码和递归解码优化分层Sketch
Sketch 是一种概率数据结构,因其在小内存条件下的高准确性而广泛应用于各个领域。为高偏度的实际数据集设计层次化数据结构是 Sketch 的主要优化方向之一。然而,现有的 Sketch 与最佳方案之间仍存在较大的准确性差距。为弥补这一差距,我们提出了一种新的 Sketch,称为 Coding Sketch。我们首次使用了层次结构和近乎无损的编码-解码来压缩频繁项,这显著提高了频繁项的准确性。此外,我们提出了无标志剪枝,以去除传统层次结构中的附加标志位。因此,Coding Sketch 可以优化频繁项和不频繁项的频率估计。我们的评估显示,在相同内存成本下,我们的算法比最新技术的准确性高出10倍。所有相关代码均已开源。
论文第一作者为bwin必赢2023级博士研究生陈齐治,通讯作者是其导师杨仝副教授。其他作者包括洪逸森(北京大学)、吴钰晗(北京大学)和崔斌教授(北京大学)。
11. Newton Sketches: 类比牛顿冷却定律在动态图中估计节点亲密度
动态图在基于不同图查询的许多实际应用中越来越重要。由于数据量大且动态性强,人们常求助于计算近似解来回答图查询。然而,以往的工作主要基于频率评估节点之间的关系,这在许多情况下是不足的。我们观察到,这种关系的变化过程与自然界中的水冷却过程非常相似。基于这一观察,我们利用牛顿冷却定律提出了一个新概念“亲密度”,以描述节点之间的关系。目前,还没有专门针对亲密度估计的算法。由于亲密度在每个时间单位内都会变化,主要挑战在于如何高效地记录和更新亲密度。本文提出了一种名为Newton-Observe的新技术来解决这一挑战。Newton-Observe的核心思想是我们仅在观察/查询时才衰减亲密度。基于Newton-Observe,我们开发了一系列Newton草图,以回答动态图中亲密度的三个基本任务。我们从理论上证明了Newton草图可以在加性常数误差范围内估计真实亲密度。我们在真实世界数据集和合成数据集上的实验表明,Newton-Observe比草率解法的相对误差缩小了最多570倍,并将吞吐量提高了最多1.62倍。所有源代码均匿名开源于Github。
论文第一作者为bwin必赢2023级博士研究生陈齐治,通讯作者是其导师杨仝副教授。其他作者包括王珂(共同一作,耶鲁大学)、李傲然(共同一作,北京大学)、吴钰晗(北京大学)和崔斌教授(北京大学)。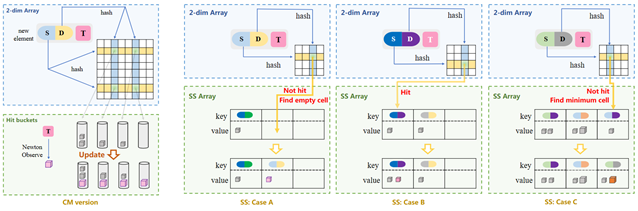
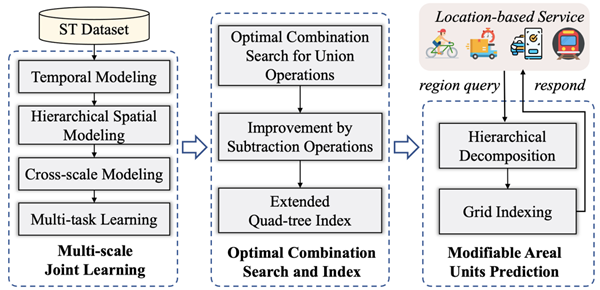
12. One4All-ST: 面向任意可变区域时空预测的统一模型
时空预测是智慧城市的核心技术之一,其旨在根据历史数据,预测未来某个时间点或时间段内特定区域内的趋势或事件。例如,交通规划者预测高峰时段的交通流量。这些预测能够帮助我们做出更加精准和高效的决策。现有的时空预测模型通常需要先对区域进行划分,这种做法存在两个主要问题:一是需要多个预测模型来处理具有不同尺度和分区的区域预测请求,导致成本高昂;二是不同模型可能会产生多个相互冲突的预测结果,造成预测混乱(即可变区域问题)。针对上述问题,本文提出了一个名为One4All-ST的框架,能够对具有任意尺度和分区的可变区域 (Modifiable Areal Units)进行时空预测,极大地提高了预测的灵活性和准确性。One4All-ST框架设计了具有层次化空间建模和尺度归一化模块的时空网络,能够高效地学习多尺度表示并降低了开发多尺度时空预测模型的成本。此外,为了解决跨尺度预测的不一致问题,本文提出了一种动态规划方案,找到使得预测误差最小化的最优组合。本研究不仅为可变区域的时空预测问题提供了新的解决方案,也为未来多尺度、多分区的城市数据分析和智能决策提供了强有力的技术支持。
论文第一作者是bwin必赢20级博士生陈李越(指导教师王乐业助理教授),合作作者包括bwin必赢23级博士生房江祎、刘腾飞(中国地质大学)、曹绍升(滴滴出行)以及bwin必赢王乐业助理教授,其中曹绍升和王乐业助理教授为本论文的通讯作者。
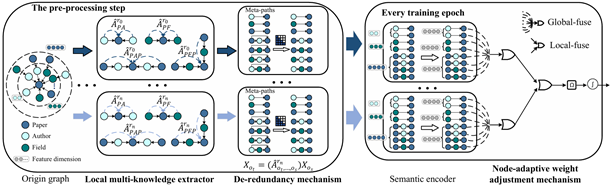
13. 面向大规模异构图的高效去冗余图神经网络架构
异构图包含丰富的语义信息,可供异构图神经网络利用。 然而,由于计算成本较高,将异构图神经网络扩展到大图具有挑战性。现有的非参数异构图神经网络在训练前使用通用子图构造方法和均值聚合器来降低复杂性。尽管取得了成功,但他们忽略了异构图的两个关键特征,导致预测性能较低。首先,他们在局部特征聚合和多个元路径的全局语义融合期间采用固定的知识提取器。此外,他们隐藏了高阶元路径的图结构信息,无法充分利用高阶全局信息。论文“HGAMLP: Heterogeneous Graph Attention MLP with De-redundancy Mechanism”,首次解决了这两个问题并提出了一种新的非参数异构神经网络框架,称为异构图注意力多层感知(HGAMLP)。 HGAMLP框架采用本地多知识提取器来增强节点表示,并利用去冗余机制从高阶元路径中提取纯图结构信息。此外,它还采用节点自适应权重调整机制来融合来自每个局部知识提取器的全局知识。在多个常用的异构图数据集上评估了HGAMLP,并表明HGAMLP在准确性和速度方面都优于最先进的基线。HGAMLP在 Open Graph Benchmark 的大型公共异构图数据集(即 Ogbn-mag)上实现了最佳性能。该论文第一作者为北京大学智能学院2021级博士生梁宇轩(指导导师为崔斌教授),作者包括张文涛、盛则昂、杨灵、童云海、崔斌,武汉大学的江佳伟。
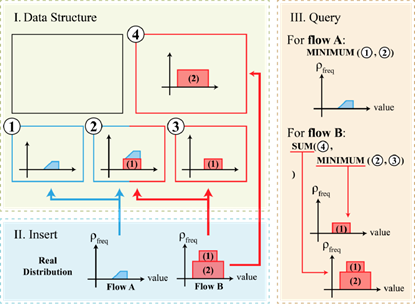
14. M4: 每流分位数估计框架
分位数估计领域因其众多实际应用而变得越来越重要。最近的研究趋势已经从单一数据流的分位数估计发展到能够同时估计多个子流(也称为每流)的数据结构。本文介绍了一种新的框架M4,旨在精确估计数据流中的每流分位数。M4是一个通用框架,可以与各种单流分位数估计算法集成,从而使这些算法能够执行每流估计。该框架采用基于Sketch的方法,提供了一种空间高效的方法来记录和提取分布信息。M4包含两种技术:MINIMUM和SUM。MINIMUM技术最小化了由于哈希冲突导致的来自其他流的噪声,而SUM技术根据流的大小高效地分类,并相应地定制处理策略。我们展示了M4在三种单流分位数估计算法(DDSketch,t-digest和ReqSketch)上的应用,详细介绍了MINIMUM和SUM技术的具体实现。我们提供了理论证明,表明M4在利用有限内存的同时提供了高准确性。此外,我们进行了广泛的实验,以评估M4在准确性和速度方面的性能。实验结果表明,在所有三个示例单流算法中,M4在每流分位数估计的准确性方面显著优于两个比较框架,同时保持了相当的速度。
论文第一作者为董思远(北京大学信息科学技术学院本科四年级),通讯作者是其导师杨仝副教授。其他作者包括樊卓宸(共同一作,北京大学)、白天宇(共同一作,北京大学)、薛寒玉(北京大学)、陈沛庆(马里兰大学)、吴钰晗(北京大学)。
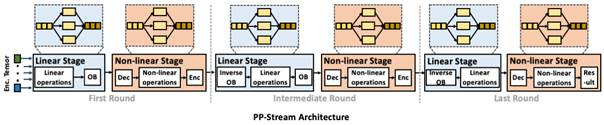
15.通过分布式流处理实现高性能隐私保护神经网络推理
随着神经网络推理在敏感数据上的应用越来越广泛,隐私保护成为一个关键问题。通常,神经网络推理需要不同方协同执行,以在敏感数据和模型上进行推理。为了实现隐私保护,通常需要用到加密技术。然而,隐私保护所需的高昂加密运算成本对神经网络推理的性能造成了巨大挑战。针对这一性能与安全之间的矛盾,论文“PP-Stream: Toward High-Performance Privacy-Preserving Neural Network Inference via Distributed Stream Processing”提出了PP-Stream,一个用于高性能隐私保护神经网络推理的分布式流处理系统。PP-Stream采用混合隐私保护机制来实现隐私保护的推理过程。具体地,PP-Stream通过同态加密和混淆机制来分别实现线性和非线性运算。为了实现低延迟的推理,它将推理数据视为实时数据流,并通过多个流水线阶段并行化推理操作,由多个服务器和线程执行。此外,PP-Stream通过优化服务器和线程之间的资源分配来实现负载均衡,实现了更高效的资源利用。实验表明,PP-Stream 在各种神经网络模型上实现了低推理延迟。PP-Stream展示了在隐私保护和高性能之间的有效平衡,为未来的隐私保护神经网络推理提供了重要参考。论文第一作者为香港中文大学一年级博士生刘青秀(导师为Patrick P. C. Lee教授),通讯作者为黄群助理教授,其他作者包括陈翔(浙江大学),王卅(中科院计算所),王文浩(中科院信工所),韩淑捷(北京大学)。
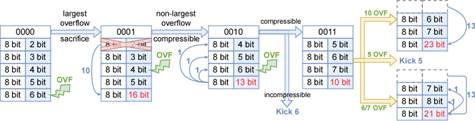
16. 通过比特级计数器调整实现精确内存分配的BitMatcher算法
随着大规模数据流处理在各种应用中的广泛应用,数据流处理算法在处理速度和内存使用方面的平衡变得尤为重要。传统的固定计数器算法,如Count-Min Sketch,通常需要分配更大的计数器,导致内存浪费。
为了解决这个问题,论文“BitMatcher: Bit-level Counter Adjustment for Sketches”提出了一种名为BitMatcher的新型算法,通过动态调整计数器大小来匹配数据流的分布,从而最大限度地提高内存利用率。BitMatcher是一种快速的全局调整算法,通过自动调整计数器的大小来匹配数据流。该算法在处理数据流时,基于独立指纹识别桶内的项目,如果发生溢出,BitMatcher会改变桶中的标志位,并以细粒度的方式动态增加或缩小某些计数器的大小。此外,BitMatcher采用类似Cuckoo hashing的理念,能够在桶内重新定位冷项目,以保留潜在的热项目,同时实现全局负载平衡。通过这种处理高度偏斜数据导致溢出的方法,BitMatcher精确操控分配的比特,实现了内存的最大化利用。实验结果表明,BitMatcher在各种网络流量数据集上,精度方面优于当前最先进的算法(SOTA),误差改善高达4个数量级,并在小数据集上依然表现出色。我们还将BitMatcher部署在多个平台上,展示了其在软件和硬件上的可扩展性和高性能。BitMatcher展示了在内存使用和精度之间的有效平衡,为未来的数据流处理提供了重要参考。
论文第一作者为清华大学一年级硕士生史奇龙(导师为徐明伟教授,联合培养导师为杨仝教授),其他作者包括贾成君(共同一作,清华大学)、李文军(鹏城实验室)、Zaoxing Liu(马里兰大学)、杨仝(北京大学)、冀佳男(北京大学)、谢高岗(中国科学院)、张伟哲(哈尔滨工业大学)、Minlan Yu(哈佛大学)。