2023年4月3日至7日,数据库领域顶级会议ICDE 2023 在美国加利福尼亚州阿纳海姆举办。bwin必赢多名教师和同学参加了此次会议,并向国际同行报告了最新研究成果,同时展开了深入的学术交流。
本届ICDE共接收论文228篇,录用率在25%左右。北京大学共发表了13篇论文,论文数量在国内高校中占比第一。其中,bwin必赢数据科学与工程研究所、网络与高能效计算研究所贡献了10篇高水平论文,其研究成果涵盖了多个领域,包括数据安全、数据流新特征挖掘、Sketch算法的参数自动化配置、基于局部编码机制的范围过滤器、面向图数据库的超快速边查询以及针对长尾用户点击率预测问题的层次兴趣建模等。
以下是论文简要内容介绍:
一、 交通流量预测的动态超图结构学习
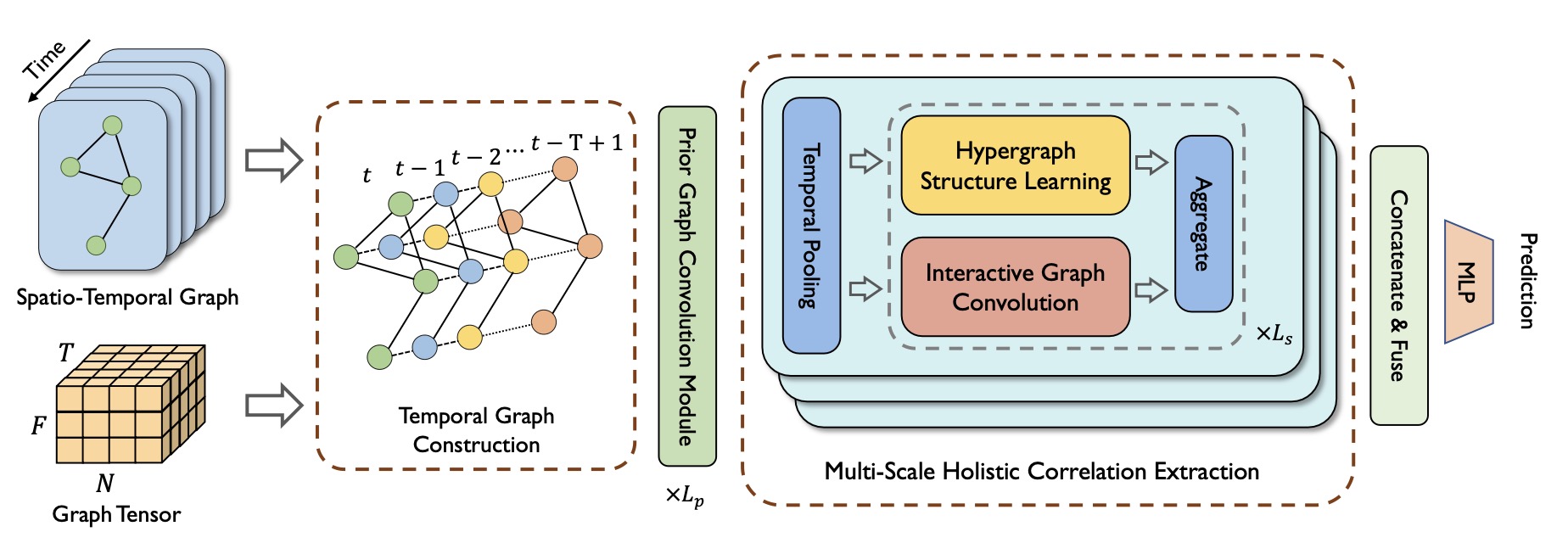
论文对交通流量预测问题进行了研究。之前的工作通常使用时空图神经网络来建模交通数据中复杂的时空相关性。然而,当涉及到复杂的交通网络时,GNN的表示能力较为有限。图在捕捉非两两关系方面是不够的。此外,现有的方法使用线性聚集邻域信息的消息传递模式,无法捕捉复杂的时空高阶交互。针对这些问题,论文提出了一种新的交通流量预测模型:动态超图结构学习(DyHSL)模型。为了学习非两两关系,论文提取超图结构信息来建模交通网络中的动态信息,并通过从其相关的超边聚合消息来更新每个节点表示。此外,为了捕捉道路网络中的高阶时空关系,论文引入了一个交互图卷积块,进一步建立了每个节点的邻域交互模型。最后,论文将这两个视图集成到一个整体的多尺度相关信息提取模块中,该模块通过不同尺度的时域池化来建模不同的时域模式。在四种常用的交通流量预测数据集的实验结果表明,与许多其他基线模型相比,论文提出的DyHSL模型是有效的。
该工作以《Dynamic Hypergraph Structure Learning for Traffic Flow Forecasting》为题,长文发表于ICDE 2023。文章共同第一作者包括bwin必赢22级硕士生赵禹昇(指导教师张铭教授)、UCLA博士后罗霄,其他合作作者包括琚玮、陈冲、华先胜、张铭(通讯作者)。
论文链接:https://juweipku.github.io/files/ICDE23_DyHSL.pdf
二、 KVSAgg:分布式键值数据的安全聚合框架
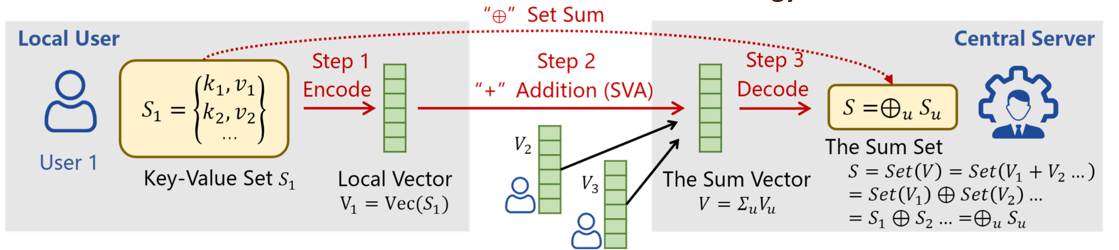
在分布式数据分析中,用户原始数据存储在本地客户端,而中央服务器需要收集全局数据统计信息。然而,在收集过程中,诚实且好奇的中央服务器可能会试图提取用户的原始数据信息,从而危及用户隐私。现有的安全聚合协议支持的数据形式有限,仅适用于向量形式或普通集合形式,导致应用范围受限。为此,论文定义了一个通用问题——键值集安全聚合。它既包含现有安全聚合问题,又涵盖许多额外场景。针对此问题,论文设计了称为KVSAgg的解决方案。它的核心思路是在键值集和向量之间双向转换数据,同时将键值集的求和操作转换为向量的加法。目前,论文在 CPU 和 GPU 平台上实现了 KVSAgg,并对三个用例进行了评估,包括联邦学习、分布式数据计数和寻找全局热点项目。 与对比方案相比,KVSAgg 在几乎所有情况下同时实现了最好的安全性、高出几个数量级的传输效率和零错误。
该工作以《KVSAgg: Secure Aggregation of Distributed Key-Value Sets》为题,发表于ICDE 2023,由文章第一作者bwin必赢21级博士生吴钰晗(指导教师杨仝长聘副教授)做口头报告,合作作者包括董思远、周易、赵义凯、符芳诚、杨仝长聘副教授(通讯作者)、牛超越博士(上交)、吴帆教授(上交)、崔斌教授。
论文链接:https://yangtonghome.github.io/uploads/ICDE23_KVSAGG.pdf

bwin必赢21级博士生吴钰晗报告现场
三、HyperCalm草图:在数据流中以一次遍历挖掘周期性批流
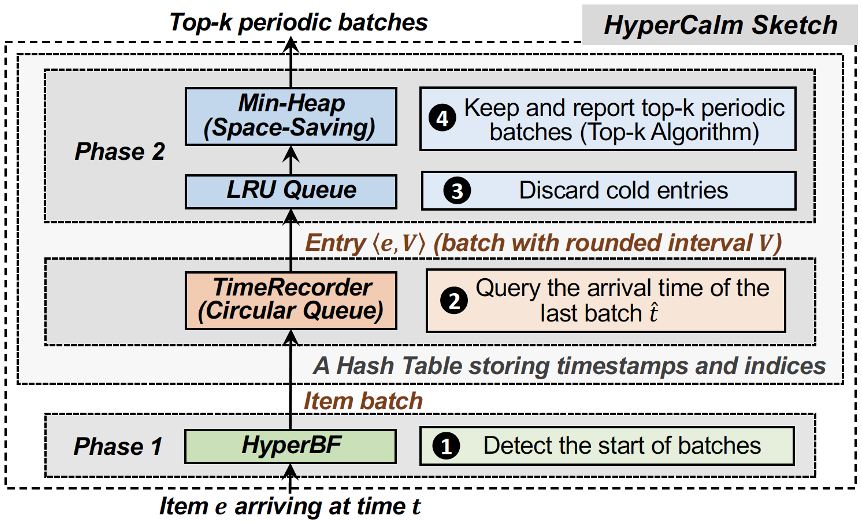
批流(batch)是数据流中一个重要的特征。一个批流指的是数据流中一组紧密到达的相同元素。论文发现,周期性到达的批流具有很大的研究价值。研究周期性批流可以帮助改善很多应用的性能,例如缓存、金融市场、在线广告、网络等。本文给出了周期性批流的正规定义,并设计了一个一次扫描的sketch算法,即HyperCalm sketch,用以检测周期性批流。HyperCalm sketch分两阶段检测周期性批流。在第一阶段,论文提出了一种可以感知时间的Bloom filter,即HyperBloomFilter,用于实时检测批流。在第二阶段,论文提出了一种增强的top-k算法,即Calm Space-Saving,用于报告top-k周期性批流。论文理论推导了HyperBF和CalmSS的误差。大量实验表明,HyperCalm在精度和速度方面相比现有方案提高4倍和13.2倍。论文还将HyperCalm应用于缓存系统,并将其集成到Apache Flink中。所有代码在GitHub上开源。
该工作以《HyperCalm Sketch: One-pass Mining Periodic Batches in Data Streams》为题,发表于今年 ICDE 的 Data Mining and Knowledge Discovery 会场,由文章第一作者bwin必赢21级博士生刘子瑞(指导教师杨仝长聘副教授)做口头报告,合作作者包括孔朝哲、杨凯程、杨仝长聘副教授(通讯作者)、缪瑞杰、陈齐治、赵义凯、屠要峰(中兴公司)、崔斌教授。
论文链接:https://yangtonghome.github.io/uploads/ICDE23_HyperCalm.pdf

bwin必赢21级博士生刘子瑞报告现场
四、Sketchconf: 一个针对sketch算法的参数自动化
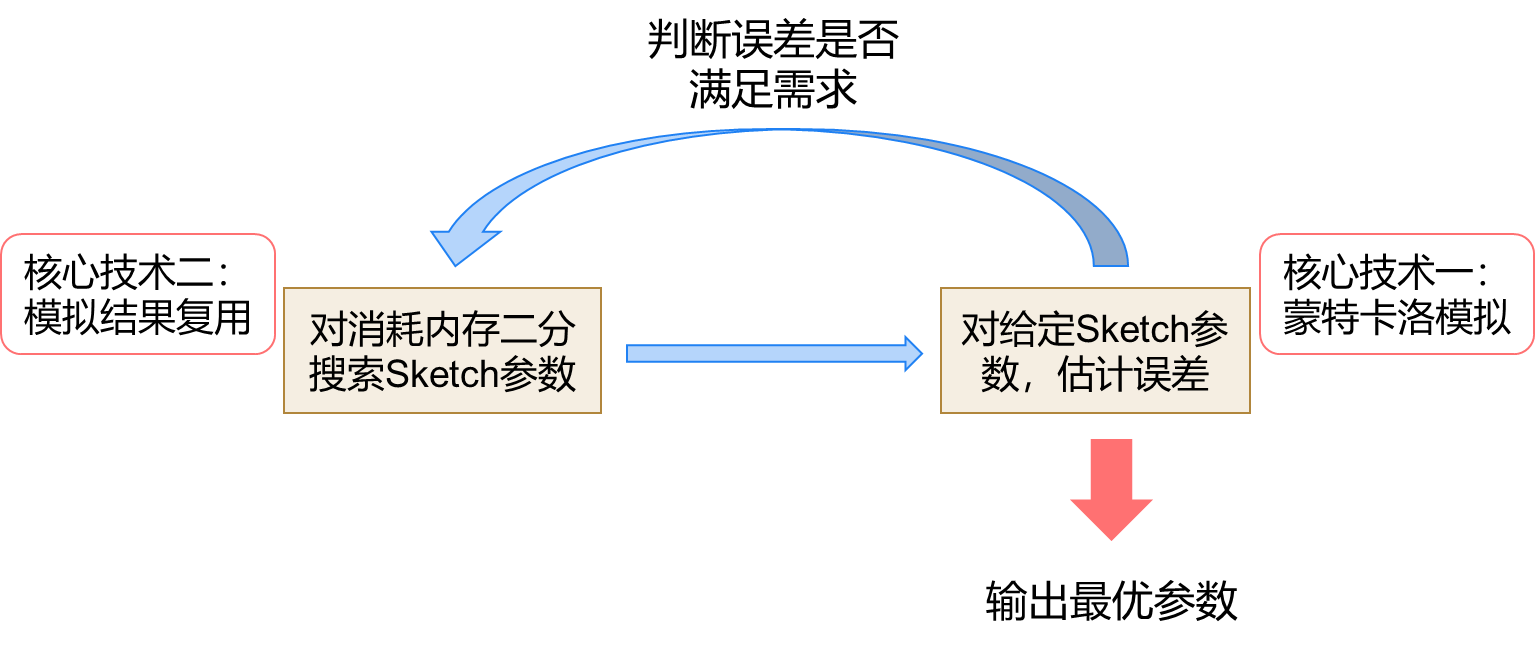
频率估计是数据流处理中的基本任务,其中Sketch算法是解决频数估计的一种重要方案。在许多情况下,用户希望在给定的误差约束下应用Sketch算法。本次报告关注的问题是,如何配置Sketch算法的参数,使得用户给定的误差约束能够得到满足。报告提出了一个自动Sketch参数配置框架,SketchConf,它能够自动、快速地生成内存最优的参数配置。SketchConf可以应用于与到来顺序无关的Sketch算法,包括CM, Count, Tower和Nitro Sketch。针对实际场景下工作负载未知且随时间变化的难点,SketchConf可与工作负载估计技术、Sketch误差监测技术相结合,应用于更加广泛的场景。实验结果表明,SketchConf的配置速度可达基准算法的715.51倍,输出配置相比理论配置可节省99.99%的内存,实现27.44倍的吞吐量。
该工作以《SketchConf: A Framework for Automatic Sketch Configuration》为题,发表于今年 ICDE,由文章共同第一作者北京大学信息科学技术学院大三本科生董丰豪(指导教师杨仝长聘副教授)做口头报告,合作作者包括缪瑞杰、赵义凯、赵一鸣、吴钰晗、杨凯程、杨仝长聘副教授(通讯作者)、崔斌教授。
论文链接:https://yangtonghome.github.io/uploads/ICDE23_SketchConf.pdf

北京大学信息科学技术学院大三本科生董丰豪报告现场
五、REncoder: 一个利用局部编码机制的时空高效的范围过滤器
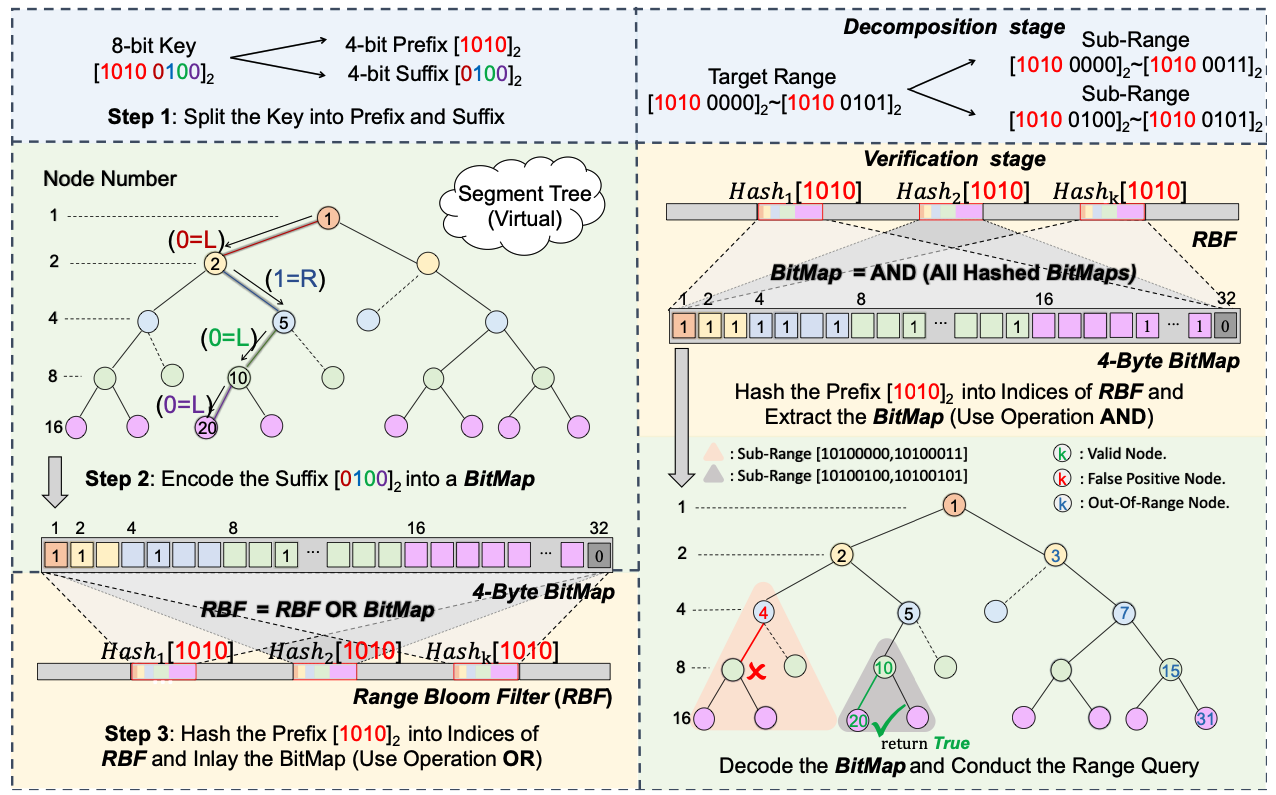
范围过滤器是一种用于回答范围成员查询的数据结构。范围查询在现代应用程序中很常见,范围过滤器可以通过滤除空范围查询来提高范围查询的性能,因此受到越来越多的关注。目前最先进的范围过滤器,如SuRF和Rosetta,分别存在高误报率和低吞吐量的缺陷。因此,论文提出了一种新的范围滤波器(REncoder)。它将所有键的前缀组织成一棵线段树,并将线段树局部地编码至布隆过滤器中以加速查询。REncoder可自适应地选择要存储的线段树的层数来支持不同的工作负载。论文从理论上证明了REncoder的误差是有界的,并推导出了其在有界误差下的渐近空间复杂度。论文在合成数据集和真实数据集上进行了实验,结果表明,REncoder优于全部现有范围滤波器。
该工作以《REncoder: A Space-Time Efficient Range Filter with Local Encoder》为题,发表于今年的ICDE中的Query Processing, Indexing, and Optimization会场,由文章第一作者北京大学前沿交叉学科研究院21级硕士生王子威(指导教师杨仝长聘副教授)进行宣讲,合作作者包括钟正、郭嘉睿、吴钰晗、李浩雨、杨仝长聘副教授(通讯作者)、屠要峰(中兴公司)、 张焕晨(清华大学)、崔斌教授
论文链接:https://yangtonghome.github.io/uploads/ICDE23_REncoder.pdf

北京大学前沿交叉学科研究院21级硕士生王子威报告现场
六、风铃索引:面向图数据库的超快速边查询
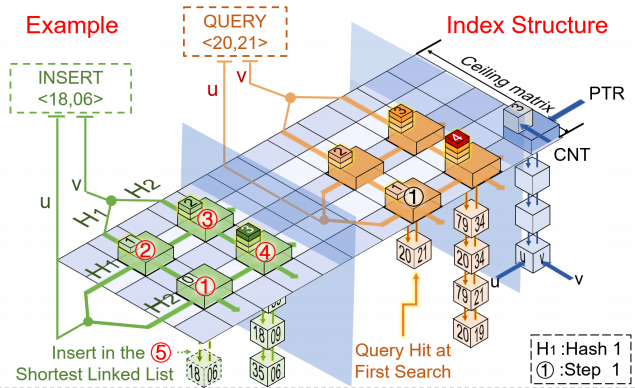
图擅长表示关系信息和结构信息,这使得图在表示各种数据方面非常强大。为了高效地存储和处理类图数据,图数据库得到了迅速的发展和广泛的研究。然而,图数据库大多使用邻接表作为其基本数据结构,由于图的扭曲的度分布可能导致边缘性能差。
针对该问题,课题组设计了风铃索引,一种内存效率高的索引数据结构,通过附加到现有的图形数据库中达到加快边查询速度的效果。在Neo4j(当今最流行的图形数据库)中进行了完整实现,并进行了多方面性能评估。结果表明,在引入风铃索引后,Neo4j数据库中平均边查询速度得到数百倍提升。
该工作以《Wind-Bell Index: Towards Ultra-Fast Edge Query for Graph Databases》为题,由文章共同第一作者北京大学前沿交叉学科研究院22级硕士生明仪(指导教师杨仝长聘副教授)做线上报告,合作作者包括邱睿、洪逸森、李浩雨、杨仝长聘副教授(通讯作者)。
论文链接:https://yangtonghome.github.io/uploads/ICDE23_WindBell.pdf
七、HIM: 针对长尾用户点击率预测问题的分层兴趣建模
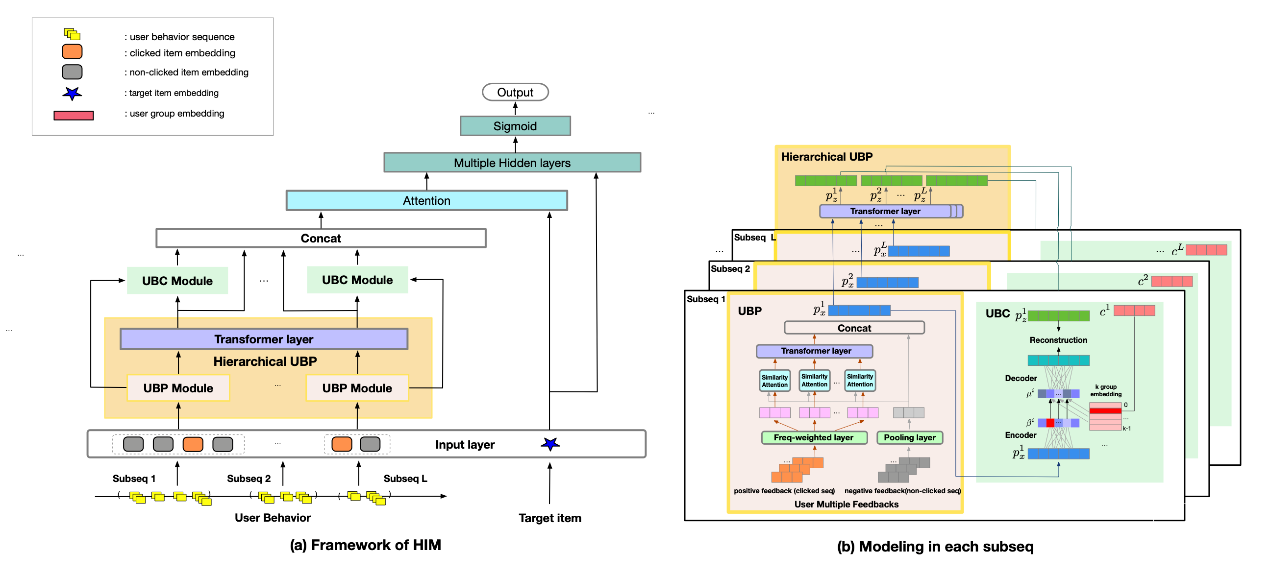
点击率预测任务旨在预测用户点击物品概率,在推荐系统中起着关键作用。解决该任务多关键步骤之一是如何从用户的历史点击行为中准确捕捉用户的偏好。然而,大多数先前的方法都侧重于帮助那些有丰富点击记录的用户,而对于很少点击物品的用户则服务不足,且这些用户在新兴电子商务公司如Lazada上占据了多数。
针对该问题,课题组设计了分层兴趣建模结构,它从个性化和群体视角出发,分层次地利用长尾用户的有限行为,并从中捕捉他们的偏好。课题组在公开数据集和工业数据集上进行了大量实验,并验证了HIM相比最先进的基准模型的优势。此外,HIM已经在Lazada推荐场景中部署,并在在线A/B测试中取得了平均3.38%的CTR性能提升。
该工作以《Hierarchical Interest Modeling of Long-tailed Users for Click-Through Rate Prediction》为题,发表于ICDE 2023,由文章第一作者bwin必赢18级博士生谢旭(指导教师崔斌教授)做口头报告,合作作者包括牛瑾(阿里)、邓丽芳(阿里)、王丹(阿里)、张建东(阿里)、吴志华(Lazada)、边凯归副教授、曹刚(智源)、崔斌教授。
论文链接:暂未公布

bwin必赢18级博士生谢旭报告现场
八、寻找数据流中的单纯形元素
论文提出了数据流中的一种新型元素,称为单纯形元素。单纯形元素在连续的p个窗口中的频率可以通过最高次数为k的多项式进行近似,其中k = 0, 1, 2。这些低阶可表示的单纯形元素具有广泛的潜在应用。例如,当k = 1时,论文可以利用这些频率呈明显线性增长或减少的元素来加速一类机器学习模型的运行时间,并检测网络攻击,如DDoS等。
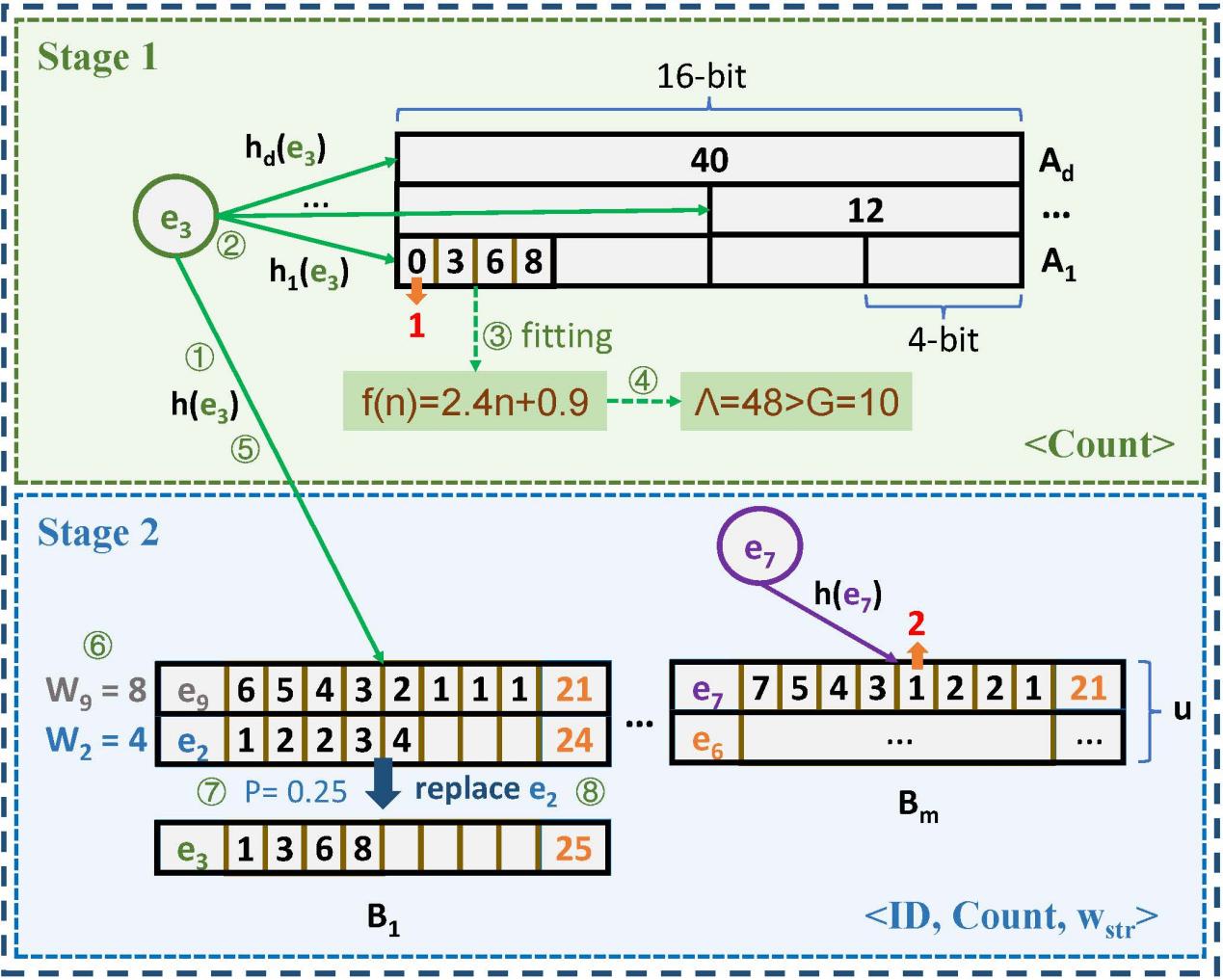
为了实时找到k阶单纯形元素,论文提出了一种新颖的sketch,即X-Sketch,以在紧凑的空间中准确记录单纯形元素。X-Sketch的关键思想是以更少的内存开销有效地过滤出非单纯形元素,然后监测剩余的潜在单纯形元素并保留那些在连续窗口中更频繁出现的元素。实验结果显示,对于k = 0, 1, 2,X-Sketch的F1得分平均比基准解决方案高出68.6%、57.9%和42.2%。最后,论文还提供了一个案例研究,通过端到端实验将X-Sketch应用于“加速”两个机器学习模型。
该工作以《Finding Simplex Items in Data Streams》为题发表于ICDE2023,由文章共同第一作者、北京大学信息科学技术学院大四本科生郭嘉睿(指导教师杨仝长聘副教授)作口头报告。文章作者还包括樊卓宸、李晓东、杨仝长聘副教授(通讯作者)、赵义凯、吴钰晗、崔斌教授、许延伟(华为),Steve Uhlig(Queen Mary University of London),张弓(华为)。
论文链接:https://yangtonghome.github.io/uploads/ICDE23_XSketch.pdf

北京大学信息科学技术学院大四本科生郭嘉睿报告现场
九、SK-Gradient:基于Sketch的分布式机器学习通信优化框架
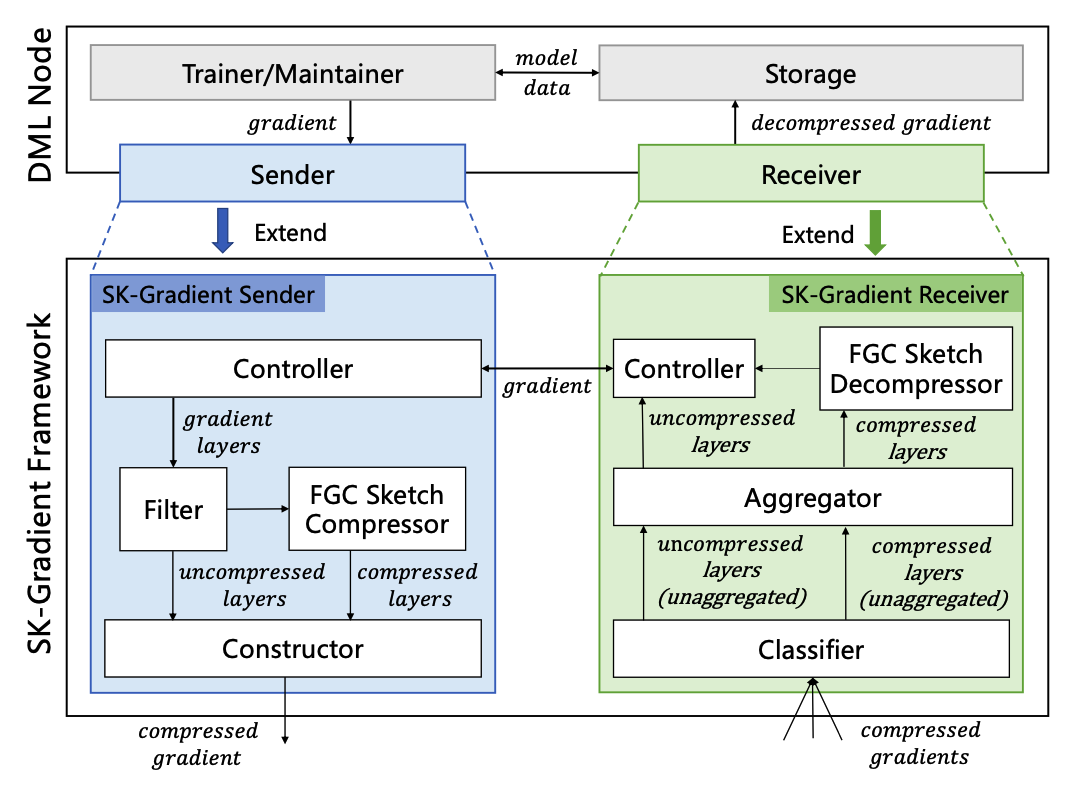
在主流的数据并行分布式机器学习系统内,各个训练节点需要高频地相互交换和聚合梯度数据以并行地优化全局模型,这导致了高额的网络通信开销。梯度压缩技术通过在节点侧压缩梯度数据能有效地降低网络通信开销,提升并行训练的效率。然而,现有的梯度压缩技术多基于量化或稀疏化方法设计,在实际使用时仍有较大局限。例如,基于量化的梯度压缩算法无法实现高的压缩比率,基于稀疏化的梯度压缩算法的计算开销过高。针对此问题,论文设计了基于Sketch的梯度压缩框架SK-Gradient。SK-Gradient的核心是一个为梯度压缩而设计的FGC Sketch。FGC Sketch以紧凑的二维数据结构存储压缩的梯度,能提供极高的压缩比率上限。同时,FGC Sketch预存储哈希结果并重复运用,消除了传统Sketch算法即时哈希计算的高额开销,进而降低了算法整体的计算开销。在FGC Sketch之外,论文也提出了选择性压缩技术和阶段性同步策略,进一步降低算法的计算开销并提升训练模型的精度。在实验部分,论文选用了四个不同的分布式机器学习训练任务来对SK-Gradient和对比算法进行评估。实验结果显示SK-Gradient拥有远低于对比算法的计算开销,在不同的压缩比率设置下均保持高的模型精度和高的训练提速优势。
该工作以《SK-Gradient: Efficient Communication for Distributed Machine Learning with Data Sketch》为题,发表于ICDE 2023,由文章第一作者bwin必赢21级博士生桂杰(指导教师黄群助理教授)做口头报告。合作作者包括信息科学技术学院三位本科生宋聿辰(20级)、王泽州(19级)、何陈泓(20级)以及bwin必赢黄群助理教授,其中黄群助理教授为本论文的通讯作者。

bwin必赢21级博士生桂杰报告现场
十、HistSketch:用于精准监控每键分布的紧凑数据结构
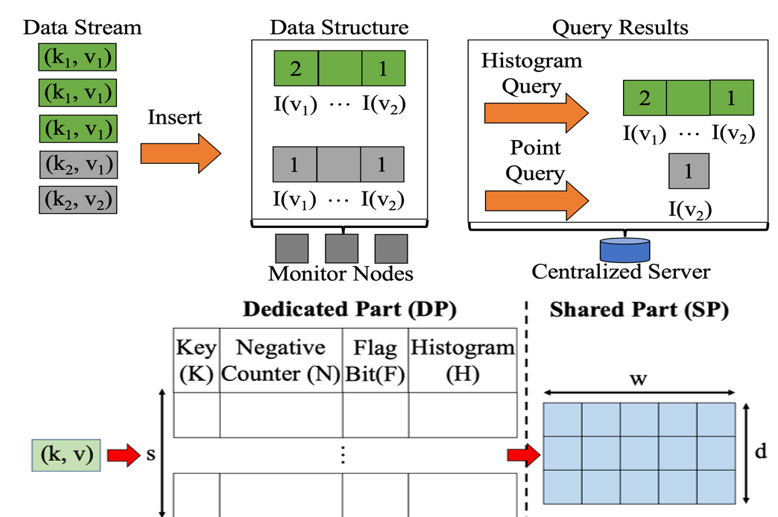
流式数据处理在数据分析领域至关重要。 然而,在流式数据处理中,有一类重要的问题——每键分布(即每个键内的数据分布),仍未解决。 传统的流式数据处理方法,如采样、直方图等,并不关注每个键内的分布情况。 Sketch算法虽然广泛应用于处理海量高速流式数据的场景,却主要计算每个键的单值特征。 但是,每键分布需要处理每个键的多个值,这会增加所需的资源。对于此问题,我们基于Sketch,设计了一种新的算法——HistSketch,用于估算每键分布。HistSketch的核心思想是区分冷热键,并使用不同功能组件来处理它们。 对于热键,HistSketch分配专用计数器,以便更精确的记录其分布。 对于冷键,HistSketch 允许计数器共享以减轻内存使用。 此外,我们为 HistSketch 提出了两种优化机制:直方图脱落机制进一步降低了存储开销,而基于方程的解码弥补了计数器共享引起的误差。 我们在实验中使用五个数据集,将 HistSketch与九种先进的基于Sketch的算法进行了比较。实验结果表明,HistSketch 在每键分布问题上实现了高精度和低资源使开销。
该工作以《HistSketch: A Compact Data Structure for Accurate Per-Key Distribution Monitoring》为题,发表于ICDE 2023,由文章第一作者bwin必赢21级博士生贺锦涛(指导教师黄群助理教授)做口头报告。合作作者包括信息科学技术学院17级本科生朱家祺以及bwin必赢黄群助理教授,其中黄群助理教授为本论文的通讯作者。

bwin必赢21级博士生贺锦涛报告现场


